機械学習のデータ処理周りの実務で、よく使う関数をまとめました。
目次
はじめに
Pandasとは
scikit-learnとは
NumPyは使わないの?
機械学習の言語はpythonでいいの?
機械学習(AI開発)の流れ
1.データの準備
データフレームを定義する(DataFrame)
csvファイルを読み込む(read_csv)
2.データの前処理
<欠損値編>
欠損値をカウントする(isunull)
欠損値を削除する(dropna)
欠損値を補完する(Imputer)
<文字列編>
文字列データを数値に変換する(map)
<外れ値編>
グラフを作成する(plot)
列の平均値/中央値を出力する(mean/median)
列の最大値/最小値を確認する(max/min)
3.データの基礎分析
データから特定の列だけを選択する(iloc/ix)
データフレームに列を追加する(’カラム名’)
4.特徴量設計
データを標準化する(StandardScaler)
相関係数を出力する(corr)
特徴量データと出力データに分割する(iloc)
学習データとテストデータに分割する(train_test_split)
目次
はじめに
Pandasとは
scikit-learnとは
NumPyは使わないの?
機械学習の言語はpythonでいいの?
機械学習(AI開発)の流れ
1.データの準備
データフレームを定義する(DataFrame)
csvファイルを読み込む(read_csv)
2.データの前処理
<欠損値編>
欠損値をカウントする(isunull)
欠損値を削除する(dropna)
欠損値を補完する(Imputer)
<文字列編>
文字列データを数値に変換する(map)
<外れ値編>
グラフを作成する(plot)
列の平均値/中央値を出力する(mean/median)
列の最大値/最小値を確認する(max/min)
3.データの基礎分析
データから特定の列だけを選択する(iloc/ix)
データフレームに列を追加する(’カラム名’)
4.特徴量設計
データを標準化する(StandardScaler)
相関係数を出力する(corr)
特徴量データと出力データに分割する(iloc)
学習データとテストデータに分割する(train_test_split)
はじめに
機械学習のPython向け外部ライブラリについて少しだけ語ります。Pandasとは
Pandasは、エクセルのようにデータを処理したり分析できるPython向けライブラリです。無料で使えて、BSDライセンスで商用利用OKで、簡単に扱えます。
参考記事:Python機械学習でなぜPandasが利用されているのか
2.データの前処理
3.データの基礎分析
4.特徴量設計
5.モデル学習・評価
本記事では1から4を紹介します。環境は、Python2.7を想定しています。環境がない方は、Anacondaでサクッとインストールしてください。Pandasもsciki-learnも一緒に入ります。
参考記事:これだけは知っておけ!PythonでAI開発の基礎まとめ
参考記事:Python機械学習でなぜPandasが利用されているのか
scikit-learnとは
scikit-learnは、機械学習の機能が詰まったPython向けライブラリです。無料で使えて、BSDライセンスなので商用利用OKで、これだけで機械学習のほぼすべてが出来る素晴らしいライブラリです。
情報弱者はIT企業が出している商用ツールを使いますが、それらの商用ツールよりはるかに柔軟で機能が豊富です。このライブラリを使えるスキルは、多分1千万円くらいの価値があります。
scikit-learnは、元々Googleのコミュニティで開発されたライブラリのため、日本語の情報がやや少ないことが難点です。実務ではかなり使われているんですけどね。
参考記事:人工知能(AI)を自社に導入したい人はscikit-learnを利用しよう
情報弱者はIT企業が出している商用ツールを使いますが、それらの商用ツールよりはるかに柔軟で機能が豊富です。このライブラリを使えるスキルは、多分1千万円くらいの価値があります。
scikit-learnは、元々Googleのコミュニティで開発されたライブラリのため、日本語の情報がやや少ないことが難点です。実務ではかなり使われているんですけどね。
参考記事:人工知能(AI)を自社に導入したい人はscikit-learnを利用しよう
NumPyは使わないの?
機械学習でよく利用されているNumPyは、計算が速いものの、実は取り扱いが結構難しいです。配列に慣れていない人が触ると、エラーがたくさん出て泣きたくなります。なので、前処理フェーズはPandasを軸にデータ処理することを強くお勧めします。機械学習の言語はPythonでいいの?
結論から言うとPython一択です。理由は3つあります。機械学習(AI開発)の流れ
1.データの準備2.データの前処理
3.データの基礎分析
4.特徴量設計
5.モデル学習・評価
本記事では1から4を紹介します。環境は、Python2.7を想定しています。環境がない方は、Anacondaでサクッとインストールしてください。Pandasもsciki-learnも一緒に入ります。
参考記事:これだけは知っておけ!PythonでAI開発の基礎まとめ
1.データの準備
まずサンプルデータを適当に作ります。データフレームを定義する(DataFrame)
Pandasを最初にインポートします。次にサンプルデータを"df"という名前で定義しました。
"df"はDataFrameの略です。
"df"はDataFrameの略です。
#pandasのインポート
import pandas as pd
#サンプルデータ作成
df = pd.DataFrame({'age' : [33, 25, 52],
'height' : [175, 170, 'NaN'],
'weight' : [70, 'NaN' , 60],
'job' : ['employee', 'neet', 'employee']})
import pandas as pd
#サンプルデータ作成
df = pd.DataFrame({'age' : [33, 25, 52],
'height' : [175, 170, 'NaN'],
'weight' : [70, 'NaN' , 60],
'job' : ['employee', 'neet', 'employee']})
csvファイルを読み込む(read_csv)
実際の業務では、csvファイルを読み込むことから始めます。read_csvで読み込めます。
しかし、現実のデータは、空白だらけ(欠損値)で、文字列が入っていて、年齢の列になぜか80,000みたいな数字(外れ値)が入っていたりします。そのため、穴を埋めてあげたり、文字を数字に置き換えたり、誤ったデータを削除したりしなければなりません。機械学習で最も人手がかかるフェーズです。
※動作させるときはcsvファイルをpandasで読み込んでください。スクリプトで定義したデータフレームですと、欠損値をNaNとして認識ないことがあります。
#サンプルデータ作成
data = '''age,height,weight,job
33,175,70,employee
25,170, ,neet
52, ,60,employee'''
#csvデータを読み込む
df = pd.read_csv('data.csv')
data = '''age,height,weight,job
33,175,70,employee
25,170, ,neet
52, ,60,employee'''
#csvデータを読み込む
df = pd.read_csv('data.csv')
2.データの前処理
前処理では、コンピュータが機械学習できるようにデータを加工処理します。基本的にコンピュータは、数字しか計算できないです。しかし、現実のデータは、空白だらけ(欠損値)で、文字列が入っていて、年齢の列になぜか80,000みたいな数字(外れ値)が入っていたりします。そのため、穴を埋めてあげたり、文字を数字に置き換えたり、誤ったデータを削除したりしなければなりません。機械学習で最も人手がかかるフェーズです。
<欠損値編>
欠損値をカウントする(isunull)
df.isnull().sum()
欠損値を削除する(dropna)
dropna関数で欠損値(nan)を含む行列を削除できます。デフォルトはaxis=0で欠損値を含む行を削除します。オプションでaxis=1を指定すると、欠損値を含む列を削除できます。
#欠損値を含む行を削除
df.dropna()
#欠損値を含む列を削除
df.dropna(axis=1)
#特定の列に欠損値が含まれている行だけを削除
df.dropna(subset=['age'])
df.dropna()
#欠損値を含む列を削除
df.dropna(axis=1)
#特定の列に欠損値が含まれている行だけを削除
df.dropna(subset=['age'])
※動作させるときはcsvファイルをpandasで読み込んでください。スクリプトで定義したデータフレームですと、欠損値をNaNとして認識ないことがあります。
欠損値を補完する(Imputer)
欠損値を削除しすぎると、データが少なくなってしまいます。そのため、欠損値を平均値で補完するやり方もあります。
#sklearnのImputerクラスのインポート
from sklearn.preprocessing import Imputer
#欠測値のインスタンスを作成
imr = Imputer(missing_values='NaN', strategy='mean', axis=0)
#データを適合
imr = imr.fit(df)
#平均値で補完を実行
imputed_data = imr.transform(df.values)
print imputed_data
<文字列編>
文字列データを数値に変換する(map)
文字列のカテゴリデータは、数値に変換が必要です。2値分類では、0と1に変換するのが一般的です。
#カテゴリデータを整数に変換
df['job'] = df['job'].map('employee':1 , 'neet':0)
<外れ値編>
外れ値の特定は2つやり方があります。1つはグラフ化してデータを眺める方法です。2つ目は、平均値と最大値/最小値を確認して、平均値よりはるかに大きい最大値/最小値が含まれていないか確認する方法です。グラフを作成する(plot)
#matplotlibをインポート
import matplotlib.pyplot as plt
#グラフを表示
df.plot()
import matplotlib.pyplot as plt
#グラフを表示
df.plot()
列の平均値/中央値を出力する(mean/median)
#平均値
df.mean()
#中央値
df.median()
df.mean()
#中央値
df.median()
列の最大値/最小値を確認する(max/min)
#最大値
max(df['age'])
#最小値
min(df['age'])
max(df['age'])
#最小値
min(df['age'])
3.データの基礎分析
データから特定の列だけを選択する(iloc/ix)
データフレームから指定した列を選択する関数は、ixとilocの2つあります。ixはカラムの名前指定が可能で、ilocは名前指定ができず列番号のみです。ixの方が汎用的に使えるので、ixだけ覚えておけば基本大丈夫です。
# ilocを使った列選択
df.iloc[:,0] # 番号で選択
df_sample.iloc[:,0:2] #複数で連番も可能
# ixを使った列選択
df.ix[:,"age"]
df.ix[:,["age","job"]]
df.ix[:,0:2]
データフレームに列を追加する('カラム名')
# 列の追加
df['home']=[1,1,0]
df['home']=[1,1,0]
4.特徴量設計(のための準備)
特徴量設計からは、データを学習していきます。そのための準備でよく使う関数を紹介します。
データの分割を図解するとこんな感じです。
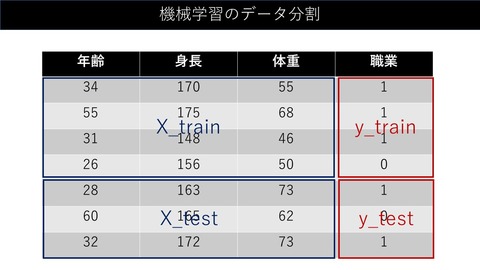
参考書籍は、Python機械学習プログラミングです。この本1冊で、実務に耐えられるスキルを身に付けることができます。

データを標準化する(StandardScaler)
学習データは、各列の尺度が同じであることが必要です。列Aの平均値が10,000で、列Bの平均値が10だとすると、列Aの影響力が強くなってしまうからです。
今回は標準化と言って、平均値0、標準偏差1になるように変換します。変換の計算式は、各データに対し、列の平均値を引いて標準偏差で割ります。標準化することで、精度の高いモデルを作成しやすくなります。
#標準化クラスをインポート
from sklearn.preprocessing import StandardScaler
ST = StandardScaler()
df = ST.fit_transform(df)
from sklearn.preprocessing import StandardScaler
ST = StandardScaler()
df = ST.fit_transform(df)
相関係数を出力する(corr)
行と行の相関係数を表示します。
df.corr()
特徴量データと出力データに分割する(iloc)
機械学習するときは、特徴量データと出力データを分割して学習させる必要があります。なので明示的にデータを分けて定義してあげましょう。#特徴量データ
X = df.iloc[:, 0:2].values
#出力データ
y = df.iloc[:,2].values
X = df.iloc[:, 0:2].values
#出力データ
y = df.iloc[:,2].values
学習データとテストデータに分割する(train_test_split)
機械学習するときは、モデルを作る学習データと、モデルを評価するテストデータに分割しておきます。学習データでテストすると、過学習の可能性があるためです。このテスト手法を、交差検証(クロスバリデーション)と言います。
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.30)
データの分割を図解するとこんな感じです。
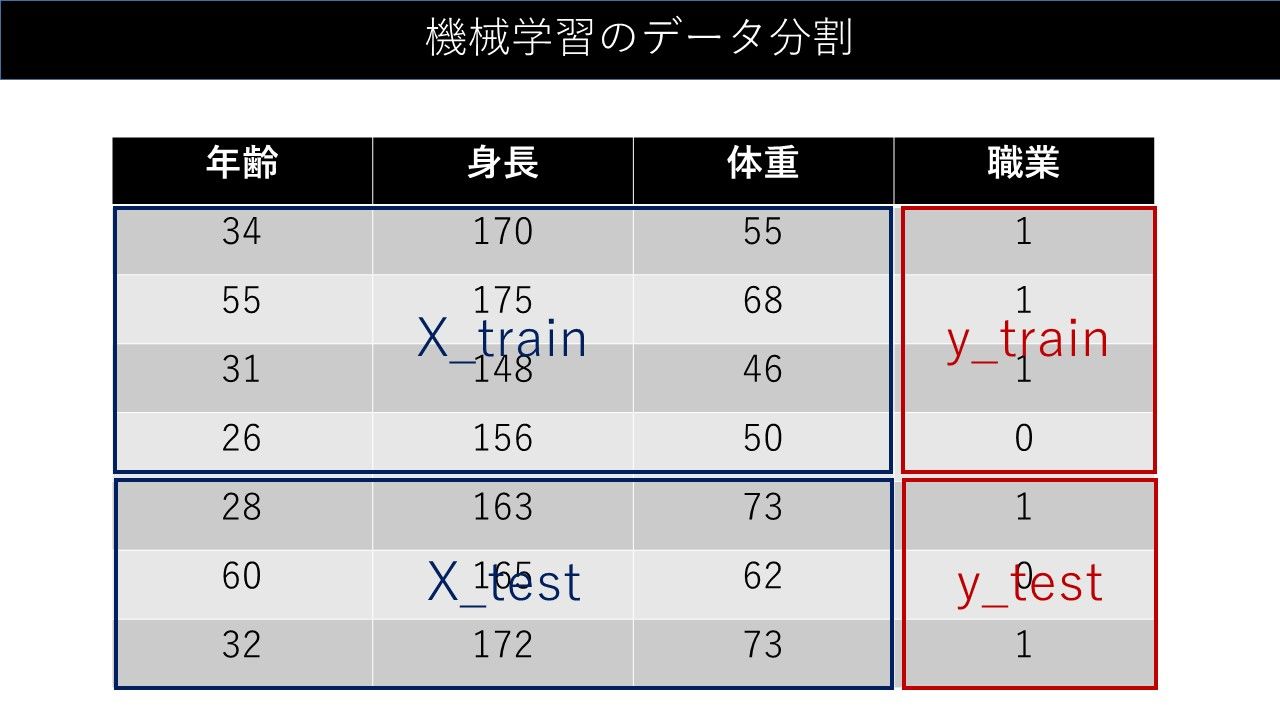
参考書籍は、Python機械学習プログラミングです。この本1冊で、実務に耐えられるスキルを身に付けることができます。
Sebastian Raschka
インプレス
2016-06-30
